

Robots.txt – это специальный файл, расположенный в корневом каталоге сайта. Вебмастер указывает в нем, какие страницы и данные закрыть от индексации от поисковых систем. Файл содержит директивы, описывающие доступ к разделам сайта (так называемый стандарт исключений для роботов). Например, с его помощью можно установить различные настройки доступа для поисковых роботов, предназначенных для мобильных устройств и обычных компьютеров. Очень важно настроить его правильно.
- Нужен ли robots.txt?
- Где лежит файл Robots.txt?
- Как создать правильный robots.txt
- Директивы Disallow и Allow
- Использование спецсимволов * и $
- Директива Sitemap
- Директива Crawl-delay
- Директива Clean-param
- Синтаксис директивы
- Директива HOST
- Правильный robots.txt: настройка
- Правильный Robots.txt пример для WordPress
- Robots.txt пример для Joomla
- Robots.txt пример для Bitrix
- Robots.txt пример для MODx
- Robots.txt пример для Drupal
- Проверить robots.txt
- Проверка robotx.txt для поискового робота Яндекса
- Проверка robotx.txt для поискового робота Google
- Генераторы robots.txt
Нужен ли robots.txt?
После того, как вы добавите свой сайт в Google и Яндекс, ПС начнут индексировать все, абсолютно все, что находится в вашей папке с сайтом на сервере. Это не очень хорошо с точки зрения продвижения, ведь в папке содержится очень много лишнего для ПС «мусора», что негативно скажется на позициях в поисковой выдаче.
Именно правильно настроенный файл robots.txt запрещает индексирование документов, папок и ненужных страниц.
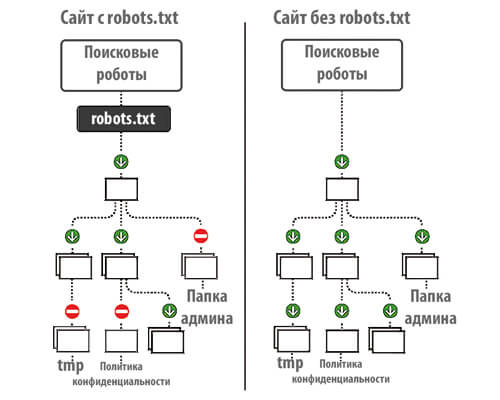
С помощью robots.txt можно:
- запретить индексирование похожих и ненужных страниц, чтобы не тратить краулинговый лимит (количество URL, которое может обойти поисковый робот за один обход). Т.е. робот сможет проиндексировать больше важных страниц.
- скрыть изображения из результатов поиска.
- закрыть от индексации неважные скрипты, файлы стилей и другие некритичные ресурсы страниц.
Если это помешает сканеру Google или Яндекса анализировать страницы, не блокируйте файлы.
Где лежит файл Robots.txt?
Если вы хотите просто посмотреть, что находится в файле robots.txt, то просто введите в адресной строке браузера: site.ru/robots.txt.

Физически файл robots.txt находится в корневой папке сайта на хостинге. У меня хостинг beget.ru, поэтому покажу расположения файла robots.txt на этом хостинге.
- Заходите на хостинг beget.ru и авторизуетесь (или регистрируетесь, если нет аккаунта).
- После выбираете Файловый менеджер.

- Находите домен вашего сайта. Далее откройте папку public_html.
- В папке должен лежать robots.txt.

Как создать правильный robots.txt
Файл robots.txt состоит из одного или нескольких правил. Каждое правило блокирует или разрешает индексирование пути на сайте.
- В текстовом редакторе создайте файл с именем robots.txt и заполните его в соответствии с представленными ниже правилами.
- Файл robots.txt должен представлять собой текстовый файл в кодировке ASCII или UTF-8. Символы в других кодировках недопустимы.
- На сайте должен быть только один такой файл.
- Файл robots.txt нужно разместить в корневом каталоге сайта. Например, чтобы контролировать индексацию всех страниц сайта
http://www.example.com/, файл robots.txt следует разместить по адресуhttp://www.example.com/robots.txt. Он не должен находиться в подкаталоге (например, по адресуhttp://example.com/pages/robots.txt). В случае затруднений с доступом к корневому каталогу обратитесь к хостинг-провайдеру. Если у вас нет доступа к корневому каталогу сайта, используйте альтернативный метод блокировки, например метатеги. - Файл robots.txt можно добавлять по адресам с субдоменами (например,
http://website.example.com/robots.txt) или нестандартными портами (например,http://example.com:8181/robots.txt). - Проверьте файл в сервисе Яндекс.Вебмастер и Google Search Console.
- Загрузите файл в корневую директорию вашего сайта.
Вот пример файла robots.txt с двумя правилами. Ниже есть его объяснение.
User-agent: Googlebot
Disallow: /nogooglebot/
User-agent: *
Allow: /
Sitemap: http://www.example.com/sitemap.xml
Объяснение
- Агент пользователя с названием Googlebot не должен индексировать каталог
http://example.com/nogooglebot/и его подкаталоги. - У всех остальных агентов пользователя есть доступ ко всему сайту (можно опустить, результат будет тем же, так как полный доступ предоставляется по умолчанию).
- Файл Sitemap этого сайта находится по адресу http://www.example.com/sitemap.xml.
Директивы Disallow и Allow
Чтобы запретить индексирование и доступ робота к сайту или некоторым его разделам, используйте директиву Disallow.
Примеры:
User-agent: Yandex
Disallow: / # блокирует доступ ко всему сайту
User-agent: Yandex
Disallow: /cgi-bin # блокирует доступ к страницам,
# начинающимся с '/cgi-bin'В соответствии со стандартом перед каждой директивой User-agent рекомендуется вставлять пустой перевод строки.
Символ # предназначен для описания комментариев. Все, что находится после этого символа и до первого перевода строки не учитывается.
Чтобы разрешить доступ робота к сайту или некоторым его разделам, используйте директиву Allow
Примеры:
User-agent: Yandex
Allow: /cgi-bin
Disallow: /
# запрещает скачивать все, кроме страниц
# начинающихся с '/cgi-bin'Недопустимо наличие пустых переводов строки между директивами User-agent, Disallow и Allow.
Директивы Allow и Disallow из соответствующего User-agent блока сортируются по длине префикса URL (от меньшего к большему) и применяются последовательно. Если для данной страницы сайта подходит несколько директив, то робот выбирает последнюю в порядке появления в сортированном списке. Таким образом, порядок следования директив в файле robots.txt не влияет на использование их роботом. Примеры:
# Исходный robots.txt:
User-agent: Yandex
Allow: /catalog
Disallow: /
# Сортированный robots.txt:
User-agent: Yandex
Disallow: /
Allow: /catalog
# разрешает скачивать только страницы,
# начинающиеся с '/catalog'# Исходный robots.txt:
User-agent: Yandex
Allow: /
Allow: /catalog/auto
Disallow: /catalog
# Сортированный robots.txt:
User-agent: Yandex
Allow: /
Disallow: /catalog
Allow: /catalog/auto
# запрещает скачивать страницы, начинающиеся с '/catalog',
# но разрешает скачивать страницы, начинающиеся с '/catalog/auto'.При конфликте между двумя директивами с префиксами одинаковой длины приоритет отдается директиве Allow.
Использование спецсимволов * и $
При указании путей директив Allow и Disallow можно использовать спецсимволы * и $, задавая, таким образом, определенные регулярные выражения.
Спецсимвол * означает любую (в том числе пустую) последовательность символов.
Спецсимвол $ означает конец строки, символ перед ним последний.
Примеры:
User-agent: Yandex
Disallow: /cgi-bin/*.aspx # запрещает '/cgi-bin/example.aspx'
# и '/cgi-bin/private/test.aspx'
Disallow: /*private # запрещает не только '/private',
# но и '/cgi-bin/private'Директива Sitemap
Если вы используете описание структуры сайта с помощью файла Sitemap, укажите путь к файлу в качестве параметра директивы sitemap (если файлов несколько, укажите все). Пример:
User-agent: Yandex Allow: / sitemap: https://example.com/site_structure/my_sitemaps1.xml sitemap: https://example.com/site_structure/my_sitemaps2.xml
Директива является межсекционной, поэтому будет использоваться роботом вне зависимости от места в файле robots.txt, где она указана.
Робот запомнит путь к файлу, обработает данные и будет использовать результаты при последующем формировании сессий загрузки.
Директива Crawl-delay
Директива работает только с роботом Яндекса.
Если сервер сильно нагружен и не успевает отрабатывать запросы робота, воспользуйтесь директивой Crawl-delay. Она позволяет задать поисковому роботу минимальный период времени (в секундах) между окончанием загрузки одной страницы и началом загрузки следующей.
Перед тем, как изменить скорость обхода сайта, выясните к каким именно страницам робот обращается чаще.
- Проанализируйте логи сервера. Обратитесь к сотруднику, ответственному за сайт, или к хостинг-провайдеру.
- Посмотрите список URL на странице Индексирование → Статистика обхода в Яндекс.Вебмастере (установите переключатель в положение Все страницы).
Если вы обнаружите, что робот обращается к служебным страницам, запретите их индексирование в файле robots.txt с помощью директивы Disallow. Это поможет снизить количество лишних обращений робота.
Директива Clean-param
Директива работает только с роботом Яндекса.
Если адреса страниц сайта содержат динамические параметры, которые не влияют на их содержимое (идентификаторы сессий, пользователей, рефереров и т. п.), вы можете описать их с помощью директивы Clean-param.
Робот Яндекса, используя эту директиву, не будет многократно перезагружать дублирующуюся информацию. Таким образом, увеличится эффективность обхода вашего сайта, снизится нагрузка на сервер.
Например, на сайте есть страницы:
www.example.com/some_dir/get_book.pl?ref=site_1&book_id=123
www.example.com/some_dir/get_book.pl?ref=site_2&book_id=123
www.example.com/some_dir/get_book.pl?ref=site_3&book_id=123Параметр ref используется только для того, чтобы отследить с какого ресурса был сделан запрос и не меняет содержимое, по всем трем адресам будет показана одна и та же страница с книгой book_id=123. Тогда, если указать директиву следующим образом:
User-agent: Yandex
Disallow:
Clean-param: ref /some_dir/get_book.plробот Яндекса сведет все адреса страницы к одному:
www.example.com/some_dir/get_book.pl?book_id=123Если на сайте доступна такая страница, именно она будет участвовать в результатах поиска.
Синтаксис директивы
Clean-param: p0[&p1&p2&..&pn] [path]В первом поле через символ & перечисляются параметры, которые роботу не нужно учитывать. Во втором поле указывается префикс пути страниц, для которых нужно применить правило.
Префикс может содержать регулярное выражение в формате, аналогичном файлу robots.txt, но с некоторыми ограничениями: можно использовать только символы A-Za-z0-9.-/*_. При этом символ * трактуется так же, как в файле robots.txt: в конец префикса всегда неявно дописывается символ *. Например:
Clean-param: s /forum/showthread.phpозначает, что параметр s будет считаться незначащим для всех URL, которые начинаются с /forum/showthread.php. Второе поле указывать необязательно, в этом случае правило будет применяться для всех страниц сайта.
Регистр учитывается. Действует ограничение на длину правила — 500 символов. Например:
Clean-param: abc /forum/showthread.php
Clean-param: sid&sort /forum/*.php
Clean-param: someTrash&otherTrashДиректива HOST
На данный момент Яндекс прекратил поддержку данной директивы.
Правильный robots.txt: настройка
Содержимое файла robots.txt отличается в зависимости от типа сайта (интернет-магазин, блог), используемой CMS, особенностей структуры и ряда других факторов. Поэтому заниматься созданием данного файла для коммерческого сайта, особенно если речь идет о сложном проекте, должен SEO-специалист с достаточным опытом работы.
Неподготовленный человек, скорее всего, не сможет принять правильного решения относительно того, какую часть содержимого лучше закрыть от индексации, а какой позволить появляться в поисковой выдаче.
Правильный Robots.txt пример для WordPress
User-agent: * # общие правила для роботов, кроме Яндекса и Google, # т.к. для них правила ниже Disallow: /cgi-bin # папка на хостинге Disallow: /? # все параметры запроса на главной Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет, # правило можно удалить) Disallow: *?s= # поиск Disallow: *&s= # поиск Disallow: /search/ # поиск Disallow: /author/ # архив автора Disallow: /users/ # архив авторов Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой # ссылки на статью Disallow: */feed # все фиды Disallow: */rss # rss фид Disallow: */embed # все встраивания Disallow: */wlwmanifest.xml # xml-файл манифеста Windows Live Writer (если не используете, # правило можно удалить) Disallow: /xmlrpc.php # файл WordPress API Disallow: *utm*= # ссылки с utm-метками Disallow: *openstat= # ссылки с метками openstat Allow: */uploads # открываем папку с файлами uploads Sitemap: http://site.ru/sitemap.xml # адрес карты сайтаUser-agent: GoogleBot # правила для Google (комментарии не дублирую) Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: */wlwmanifest.xml Disallow: /xmlrpc.php Disallow: *utm*= Disallow: *openstat= Allow: */uploads Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета) Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета) Allow: /wp-*.png # картинки в плагинах, cache папке и т.д. Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д. Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS User-agent: Yandex # правила для Яндекса (комментарии не дублирую) Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: */wlwmanifest.xml Disallow: /xmlrpc.php Allow: */uploads Allow: /*/*.js Allow: /*/*.css Allow: /wp-*.png Allow: /wp-*.jpg Allow: /wp-*.jpeg Allow: /wp-*.gif Allow: /wp-admin/admin-ajax.php Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать # от индексирования, а удалять параметры меток, # Google такие правила не поддерживает Clean-Param: openstat # аналогично
Robots.txt пример для Joomla
User-agent: *
Disallow: /administrator/
Disallow: /cache/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /xmlrpc/
Sitemap: http://путь к вашей карте XML формата
Robots.txt пример для Bitrix
User-agent: *
Disallow: /*index.php$
Disallow: /bitrix/
Disallow: /auth/
Disallow: /personal/
Disallow: /upload/
Disallow: /search/
Disallow: /*/search/
Disallow: /*/slide_show/
Disallow: /*/gallery/*order=*
Disallow: /*?print=
Disallow: /*&print=
Disallow: /*register=
Disallow: /*forgot_password=
Disallow: /*change_password=
Disallow: /*login=
Disallow: /*logout=
Disallow: /*auth=
Disallow: /*?action=
Disallow: /*action=ADD_TO_COMPARE_LIST
Disallow: /*action=DELETE_FROM_COMPARE_LIST
Disallow: /*action=ADD2BASKET
Disallow: /*action=BUY
Disallow: /*bitrix_*=
Disallow: /*backurl=*
Disallow: /*BACKURL=*
Disallow: /*back_url=*
Disallow: /*BACK_URL=*
Disallow: /*back_url_admin=*
Disallow: /*print_course=Y
Disallow: /*COURSE_ID=
Disallow: /*?COURSE_ID=
Disallow: /*?PAGEN
Disallow: /*PAGEN_1=
Disallow: /*PAGEN_2=
Disallow: /*PAGEN_3=
Disallow: /*PAGEN_4=
Disallow: /*PAGEN_5=
Disallow: /*PAGEN_6=
Disallow: /*PAGEN_7=
Disallow: /*PAGE_NAME=user_post
Disallow: /*PAGE_NAME=detail_slide_show
Disallow: /*PAGE_NAME=search
Disallow: /*PAGE_NAME=user_post
Disallow: /*PAGE_NAME=detail_slide_show
Disallow: /*SHOWALL
Disallow: /*show_all=
Sitemap: http://путь к вашей карте XML формата
Robots.txt пример для MODx
User-agent: *
Disallow: /assets/cache/
Disallow: /assets/docs/
Disallow: /assets/export/
Disallow: /assets/import/
Disallow: /assets/modules/
Disallow: /assets/plugins/
Disallow: /assets/snippets/
Disallow: /install/
Disallow: /manager/
Sitemap: http://site.ru/sitemap.xml
Robots.txt пример для Drupal
User-agent: *
Disallow: /database/
Disallow: /includes/
Disallow: /misc/
Disallow: /modules/
Disallow: /sites/
Disallow: /themes/
Disallow: /scripts/
Disallow: /updates/
Disallow: /profiles/
Disallow: /profile
Disallow: /profile/*
Disallow: /xmlrpc.php
Disallow: /cron.php
Disallow: /update.php
Disallow: /install.php
Disallow: /index.php
Disallow: /admin/
Disallow: /comment/reply/
Disallow: /contact/
Disallow: /logout/
Disallow: /search/
Disallow: /user/register/
Disallow: /user/password/
Disallow: *register*
Disallow: *login*
Disallow: /top-rated-
Disallow: /messages/
Disallow: /book/export/
Disallow: /user2userpoints/
Disallow: /myuserpoints/
Disallow: /tagadelic/
Disallow: /referral/
Disallow: /aggregator/
Disallow: /files/pin/
Disallow: /your-votes
Disallow: /comments/recent
Disallow: /*/edit/
Disallow: /*/delete/
Disallow: /*/export/html/
Disallow: /taxonomy/term/*/0$
Disallow: /*/edit$
Disallow: /*/outline$
Disallow: /*/revisions$
Disallow: /*/contact$
Disallow: /*downloadpipe
Disallow: /node$
Disallow: /node/*/track$
Disallow: /*&
Disallow: /*%
Disallow: /*?page=0
Disallow: /*section
Disallow: /*order
Disallow: /*?sort*
Disallow: /*&sort*
Disallow: /*votesupdown
Disallow: /*calendar
Disallow: /*index.php
Allow: /*?page=
Disallow: /*?
Sitemap: http://путь к вашей карте XML формата
ВНИМАНИЕ!
CMS постоянно обновляются. Возможно, понадобиться закрыть от индексации другие страницы. В зависимости от цели, запрет на индексацию может сниматься или, наоборот, добавляться.
Проверить robots.txt
У каждого поисковика свои требования к оформлению файла robots.txt.
Для того, чтобы проверить robots.txt на корректность синтаксиса и структуры файла, можно воспользоваться одной из онлайн-служб. К примеру, Яндекс и Google предлагают собственные сервисы анализа сайта для вебмастеров, которые включают анализ robots.txt:
Проверка robotx.txt для поискового робота Яндекса
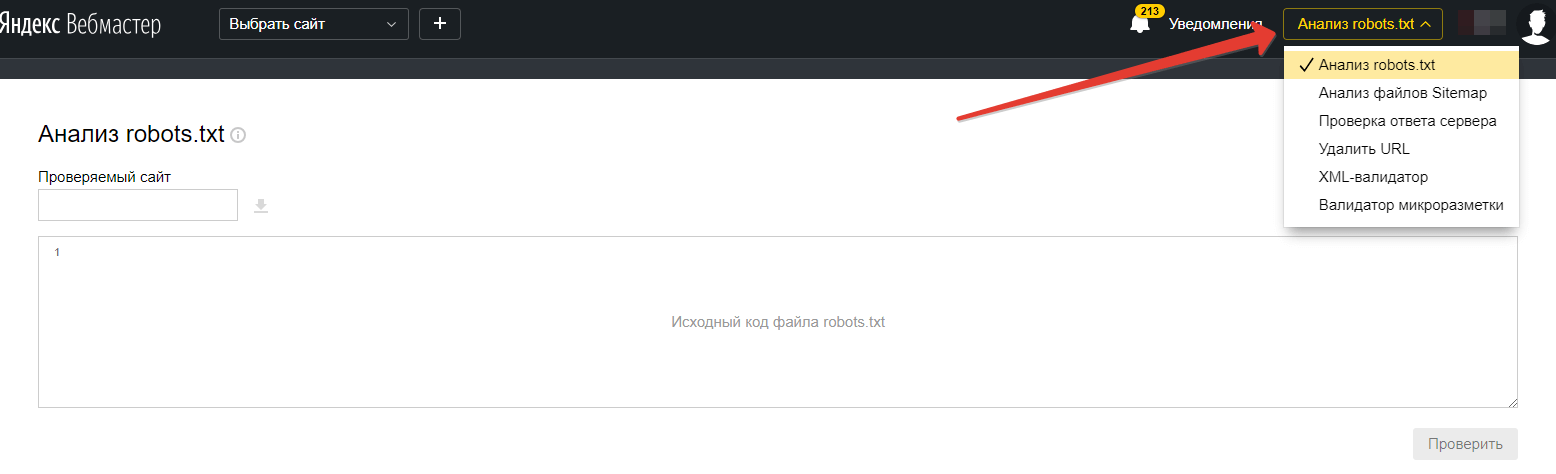
Сделать это можно при помощи специального инструмента от Яндекс — Яндекс.Вебмастер, еще и двумя вариантами.
Вариант 1:
Справа вверху выпадающий список – выберите Анализ robots.txt или по ссылке http://webmaster.yandex.ru/robots.xml
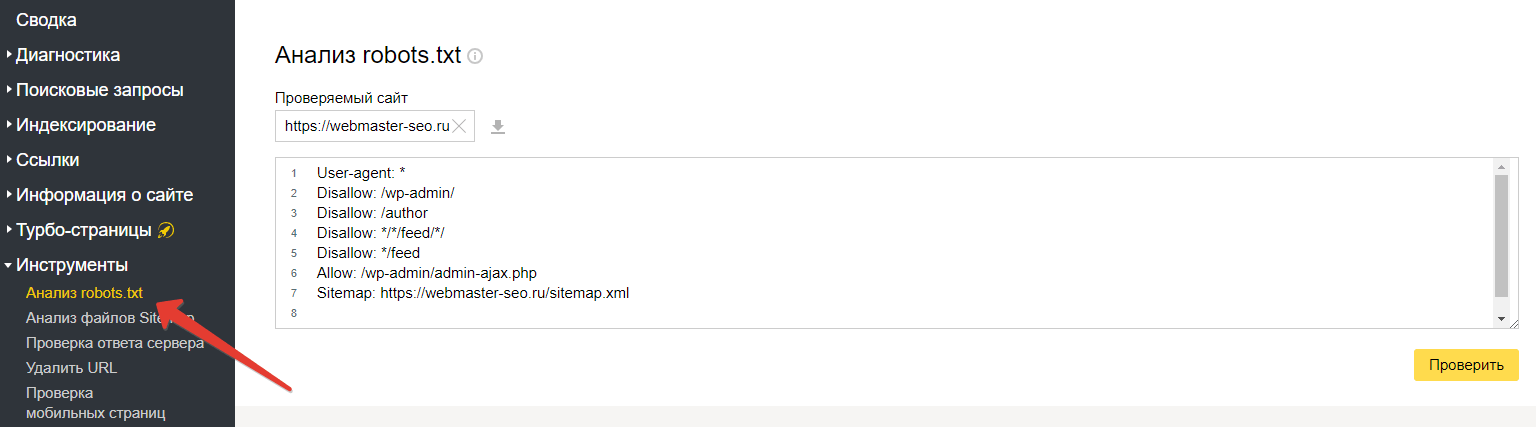
Вариант 2:
Этот вариант подразумевает, что ваш сайт добавлен в Яндекс Вебмастер и в корне сайта уже есть robots.txt.
Слева выберите Инструменты — Анализ robots.txt
Не стоит забывать о том, что все изменения, которые вы вносите в файл robots.txt, будут доступны не сразу, а спустя лишь некоторое время.
Проверка robotx.txt для поискового робота Google
Проверка файла robots.txt в Google: https://www.google.com/webmasters/tools/siteoverview?hl=ru
- В Google Search Console выберите ваш сайт, перейдите к инструменту проверки и просмотрите содержание файла
robots.txt. Синтаксические и логические ошибки в нем будут выделены, а их количество – указано под окном редактирования. - Внизу на странице интерфейса укажите нужный URL в соответствующем окне.
- В раскрывающемся меню справа выберите робота.
- Нажмите кнопку ПРОВЕРИТЬ.
- Отобразится статус ДОСТУПЕН или НЕДОСТУПЕН. В первом случае роботы Google могут переходить по указанному вами адресу, а во втором – нет.
- При необходимости внесите изменения в меню и выполните проверку заново. Внимание! Эти исправления не будут автоматически внесены в файл robots.txt на вашем сайте.
- Скопируйте измененное содержание и добавьте его в файл robots.txt на вашем веб-сервере.

Кроме сервисов проверки от Яндекс и Google, существует множество других онлайн валидаторов robots.txt.
Генераторы robots.txt
- Сервис от SEOlib.ru.С помощью данного инструмента можно быстро получить и проверить ограничения в файле Robots.txt.
- Генератор от pr-cy.ru.В результате работы генератора Robots.txt вы получите текст, который необходимо сохранить в файл под названием Robots.txt и загрузить в корневой каталог вашего сайта.







Здравствуйте Алексей, понравилась ваша материал по созданию robots.txt : статья очень подробная с разъяснениями как создать самостоятельно, но кроме этого приведены примеры роботса в различных движках, который можно скопировать. Правда копирование не совсем удобное. Копируются и ваши комменты. Но все разно БОЛЬШОЕ СПАСИБО за вашу статью. Хотелось бы уточнить: во многих примерах роботса помимо sitemap указывается еще и ссылка на host. У вас этого нет. Почему?
P/S/ Я еще новичек в деле сайтостроения. Только создаю свой блог и пока закрыл его для поисковых систем. Сейчас делаю роботс и карту.
Здравствуйте, Эдуард.
Рад, что статья оказалась полезной)
Host – это директива, которая ранее использовалась Яндексом. Но не так давно, Яндекс отказался от использования этой директивы. Собственно, поэтому я не включил в статью Host 🙂
Спасибо вам. Удачи во всех ваших проектах!
Здравствуйте Алексей. С последней нашей с вами переписки прошло уже без малого 9 месяцев. Использую на сайте ваш robot.txt однако в последние месяцы меня все больше терзают смутные сомнения по предложенной для гугла концовке:
Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать # от индексирования, а удалять параметры меток, # Google такие правила не поддерживает Clean-Param: openstat # аналогично
Я эти команды указал. Одноко сейчас обнаружил, что гугл при проверке роботса показывавет на эти две строки как ошибку. Да и индексация сайта по яндексу и гуглу у меня небо и земля в пользу яндекса. Разрыв просто существенный. У меня по яндексу заходят порядка 90% пользователей.
Здравствуйте.
Если вы указали для GoogleBot – Clean-Param, то он просто не понимает этой команды.
Если вы загружаете весь файл на проверку гугла и в ней есть конструкция Clean-Param, то, конечно, он будет ругать на эти строки.
С индексацией надо смотреть – из-за Clean-Param – это не может быть.